RAGとは?仕組み・ベクトルDB・最新動向まで完全解説 (2026年版)
要点 (30秒で読める答え): RAGとは、LLMが回答前に外部データを検索し、結果をプロンプトに入れて生成する「検索拡張生成」です。2026年はStandard RAGを基本に、Agentic RAG・Graph RAG・CAGへ発展しています。
この記事のポイント RAGは「LLMに外部知識を後付けする」技術。2026年はStandard RAGが基本形のまま、Agentic RAG・Graph RAG・CAG(Cache-Augmented Generation)の3方向に分岐している。社内導入で詰まるのはモデル選びではなく、ベクトルDBとチャンク設計の地味な部分だ。
ChatGPTに自社マニュアルを読ませたら平気でデタラメを返してきた、という相談がここ2年で激増している。原因のほとんどは「LLMがそのデータを学習していない」こと。RAG(Retrieval-Augmented Generation/検索拡張生成)はこの問題に対する有力な解決策の一つで、2026年時点で社内向け生成AIで広く採用されているアーキテクチャになっている(他に長コンテキストモデルの直接投入、検索APIとの組み合わせ、ファインチューニング併用などの選択肢もある)。
ただし「RAGを入れれば賢くなる」という売り文句は半分嘘だ。検索の精度が低ければLLMはむしろ堂々とハルシネーションを起こす。本記事では仕組みの本質、ベクトルDBの選び方、2026年に登場した派生アーキテクチャ、そして導入コストの現実までまとめて整理する。
RAGとは何か:定義と一行解説

RAGとは、LLMが回答を生成する前に外部データベースから関連情報を検索し、その検索結果をプロンプトに注入してから生成させる仕組みです。日本語では「検索拡張生成」と訳される。
要するに「LLMに毎回カンペを渡してから喋らせる」だけの技術なのだが、これが破格に効く。LLMの学習データに含まれていない社内文書、最新ニュース、専門知識をリアルタイムで参照させられるからだ。
ファインチューニングとの違いはここで明確になる。ファインチューニングはモデル自体に知識を焼き付ける重い作業だが、RAGは外部データを差し替えるだけで済む。情報が頻繁に更新される業務ではRAGが向くケースが多いが、文体最適化やタスク特化ではファインチューニング、定型応答ではキャッシュやルールベースが適することもあり、併用設計が現実的。
RAGが必要とされる3つの理由

LLM単体には構造的な弱点が3つある。RAGはそのすべてに直接効く。
- 学習データの鮮度問題: GPT-4o系もClaude Opus 4系も学習データには必ずカットオフがある(各モデルの正確なカットオフ日は公式ドキュメント参照、2026-05時点)。昨日リリースされた製品の話はできない
- ハルシネーション: 知らないことを「知らない」と言わず、それっぽく作文する癖がある
- 社内データへの非対応: 社外秘の規程書や顧客データはモデルが学習していない
RAGはこの3点に対し、検索結果という外部の事実をLLMに渡すことで答えさせる。回答の根拠ドキュメントを引用付きで返せるようになる点は、エンタープライズ用途で特に重宝される。
逆に言うと、雑談や創作のようにそもそも事実を必要としないタスクではRAGは要らない。導入を検討する前に「そのユースケースは本当にRAG向きか」を疑った方がいい。
RAGの仕組み:5ステップで動作を分解する

RAGの内部動作は、抽象化するとシンプルな5ステップに収まる。
- インデックス構築(事前処理): 社内文書を細かく分割(チャンク化)し、埋め込みモデルでベクトル化してベクトルDBに保存
- クエリ受付: ユーザーの質問を同じ埋め込みモデルでベクトル化
- 類似検索(Retrieval): ベクトルDBで意味的に近いチャンクを上位数件取得
- プロンプト構築: 取得したチャンクを「参考情報」としてLLMに渡すプロンプトに組み込む
- 生成(Generation): LLMが参考情報をもとに回答を生成
地味だがステップ1のチャンク設計が品質を9割決める。チャンクが大きすぎると関係ない情報まで引っ張られてノイズになり、小さすぎると文脈が切れて意味が通らなくなる。日本語文書では300〜800文字程度が一つの目安になる。
検索のRecall(取りこぼしの少なさ)が低ければ、その後ろのLLMがどれだけ優秀でも答えられない。「RAGの品質=検索の品質」と覚えておいて間違いない。
ベクトルDBの役割と主要選択肢
ベクトルDBは、テキストを数値の配列(埋め込みベクトル)として保存し、意味的な類似度で検索できる専用データベースのこと。RAGの心臓部にあたる。
通常のRDBが「キーワード一致」で検索するのに対し、ベクトルDBは「意味の近さ」で検索する。「年休の申請方法」と「有給はどう取るんですか」が同じ文書にヒットするのはこれのおかげだ。
主要な選択肢を比較する。導入規模と運用負荷で選ぶのが現実的。
| ベクトルDB | 形態 | 特徴 | 向いているケース |
|---|---|---|---|
| Pinecone | マネージド | セットアップが速く運用負荷が低い | スピード重視のSaaS開発 |
| Weaviate | OSS/マネージド両対応 | ハイブリッド検索が強い | 中〜大規模で柔軟性が欲しい |
| Qdrant | OSS中心 | 高速・軽量、Rust製 | オンプレ要件あり |
| Milvus | OSS | 大規模スケール対応 | 大規模ベクトル運用 |
| pgvector | PostgreSQL拡張 | 既存DBに追加可能 | 小〜中規模、運用統合 |
※各製品の最新仕様・スケール上限は2026-05時点で公式ドキュメントを参照。
中小規模ならpgvectorで始めて困ったらQdrant/Weaviateに移行、というルートが2026-05時点では候補として有力(料金体系は各社更新されるため公式ページで要確認)。PoC段階からマネージド一択に決め打ちすると課金が膨らみがちなので、要件と運用体制で比較したい。
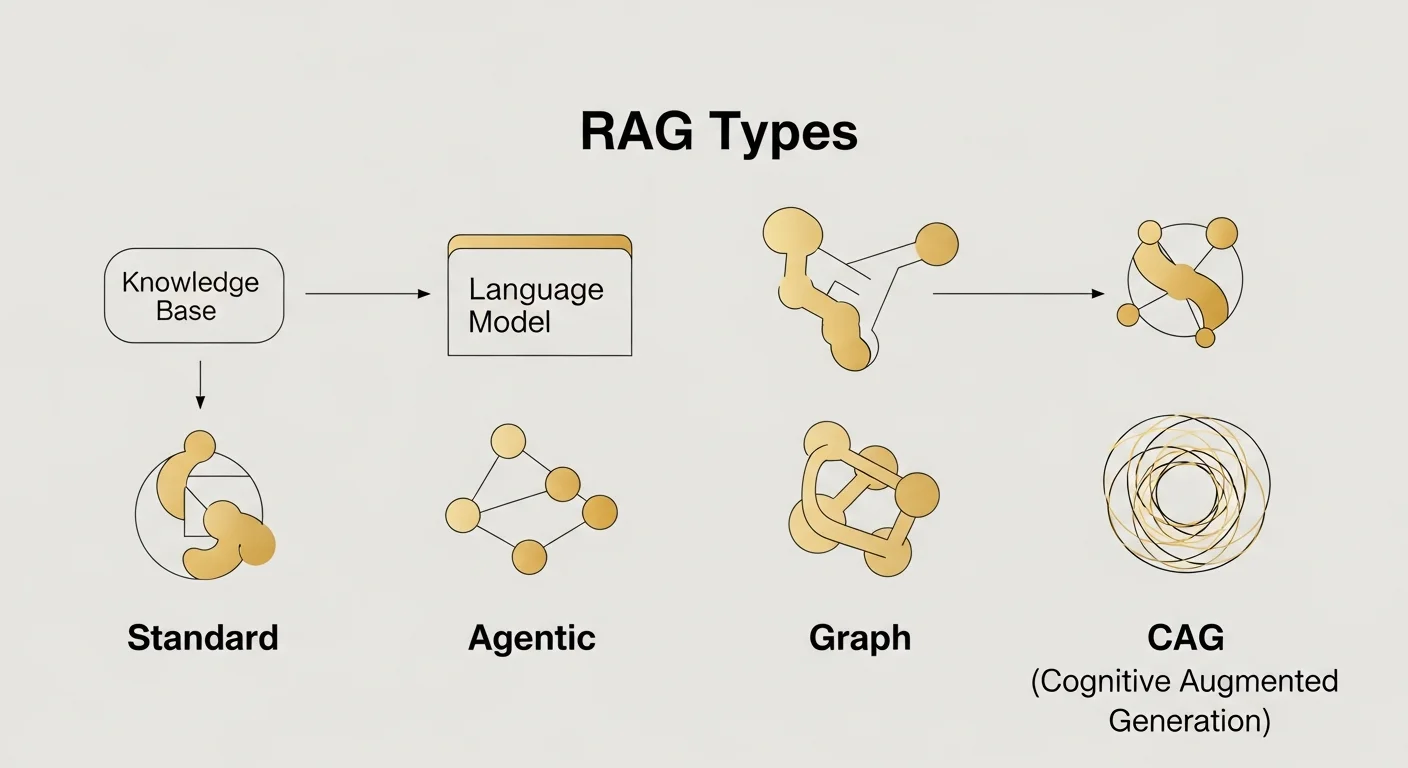
RAGの種類:Standard / Agentic / Graph / CAG
2026-05時点で、RAGアーキテクチャは大きく4方向に派生していると一部で整理されている(呼称や分類はベンダー・論文により異なる)。それぞれ得意分野が違うので、用途で選び分ける。
| 項目 | CAG(Cache-Augmented Generation) | Standard RAG | Agentic RAG | Graph RAG |
|---|---|---|---|---|
| 処理方式 | 知識ベースをLLMコンテキストに事前キャッシュ | クエリごとに検索→生成 | エージェントが計画・検索・検証を反復 | エンティティグラフを構築し関係性を横断検索 |
| 応答速度 | キャッシュヒット時は検索を省けるため高速(具体値はモデル・文書量・実行環境で大きく異なる、公式ベンチ参照) | 検索+生成の二段構成で中程度(条件により変動) | 数分〜(反復回数とタスク複雑度に依存) | 中程度(グラフ構築に初期コスト) |
| 適用場面 | FAQ、製品カタログ、社内規定など静的データ | 汎用的な質問応答 | 法務分析、金融調査 | 関係性重視の調査・研究 |
要点を一言でまとめると、静的なFAQはCAG、汎用QAはStandard、複雑タスクはAgentic、関係性追跡はGraph。ベンダー提案で「とりあえずAgentic RAG」と言われたら一度立ち止まった方がいい。コストも応答時間も跳ね上がる。
Agentic RAGは確かに強力で、自律エージェントが「足りない情報を追加検索する」「矛盾を自分で検証する」といった反復動作をこなす。ただ実装難度は段違いに高く、運用観測性も別格に難しくなる。詳細は autogpt-complete-guide-2026 で扱った自律エージェント論と地続きの議論になる。
主要RAGフレームワーク比較(2026年版)
フレームワークの選び方で詰まる人が一番多いので、用途別に整理する。
- LangChain: 最もエコシステムが広い。プロトタイピング最速。ただし規模が大きくなると抽象化が裏目に出る
- LlamaIndex: ドキュメント処理に特化。インデックス構築の選択肢が圧倒的
- Haystack: 構造的なパイプライン設計を強制する。金融・医療・法務・行政のような間違えられない領域で強い
- RAGatouille: ColBERTベースのトークンレベル検索を簡単に組み込める軽量Python製
- DSPy: プロンプト自動最適化。職人芸の脱却に効く
PoCはLangChainかLlamaIndexで素早く立ち上げ、本番運用が見えたタイミングでHaystackやカスタム実装に移る、という二段構えが鉄板。最初から完璧な設計を目指すと永久にローンチできない。
RAG導入のコスト構造
導入コストは要件・データ量・地域・ベンダーで大きく変動し、PoCから本格導入まで桁単位で幅が出る(具体額は2026-05時点で各SIer・ベンダーの見積もり前提を確認のこと)。内訳を理解せずに見積もりを取ると揉めやすい。
主な費用項目はこう分解できる。
- 初期構築: 要件定義、データ整備、チャンク設計、埋め込み選定、UI構築
- インフラ: ベクトルDB、ストレージ、ホスティング
- API利用料: 埋め込みモデル、生成LLM(クエリごとに課金される)
- 運用: 文書更新、再インデックス、評価、改善
- データ整備の人件費: ここを甘く見ると確実に失敗する
特にAPI利用料は地味に効いてくる。長文ドキュメントを毎回コンテキストに含めるRAGは、トークン消費が普通のチャット用途より一桁多い。Anthropicのプロンプトキャッシュのような仕組みを使うと劇的に下げられるので、本番運用前に必ず検証する。
import anthropic
client = anthropic.Anthropic()
KNOWLEDGE_BASE = """
[ここに参照させたい長いドキュメントを入れる]
...(数千〜数万トークン)
"""
def ask_with_cache(user_query: str) -> str:
response = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=1024,
system=[
{
"type": "text",
"text": KNOWLEDGE_BASE,
"cache_control": {"type": "ephemeral"}
}
],
messages=[{"role": "user", "content": user_query}]
)
return response.content[0].text
このようにナレッジ部分をキャッシュ対象にすると、2回目以降のリクエストでトークンコストが大幅に下がる。RAGのように「長い文書をコンテキストに含める」用途では特に効果が大きい。
RAGがハマる業務・ハマらない業務
RAGの向き不向きは意外とハッキリしている。
ハマる業務:
- カスタマーサポート(FAQ、製品マニュアル参照)
- 社内規程・人事制度の問い合わせ対応
- 営業向けの提案書ドラフト生成
- 法務・契約書レビューの一次チェック
ハマらない業務:
- 計算・数値処理(LLMの苦手分野が直接出る)
- 関係性が複雑なグラフ的データ(→ Graph RAGを検討)
- リアルタイム性が必須の業務(応答数秒の壁)
OCR連携によるドキュメント取り込みもRAG構築でよくある論点で、紙文書中心の業務なら ai-ocr-tools-guide-2026 で扱ったAI OCRと組み合わせる前提で設計するのが現実解。動画・画像のマルチモーダル検索を絡める場合は sora-ai-guide-2026 や meta-ai-guide-2026 で議論されているマルチモーダルLLMの進化が前提になってくる。
RAG構築の実践手順(社内向けPoCの最短ルート)
PoCを最短で回す現実的な手順はこれ。
- 対象ドキュメントを20〜100本に絞る: 最初から全社データを入れない。失敗の温床
- PDF/Word/Markdownを統一フォーマットに変換: 表・画像はOCR or構造化抽出
- チャンク化: 300〜800文字、見出し単位で分割
- 埋め込み: 日本語ならOpenAI text-embedding-3-large、Cohere multilingual、ローカルならBGE系
- ベクトルDBに登録: 最初はpgvectorかQdrantで十分
- 検索→プロンプト→LLM: LangChainかLlamaIndexで30行程度のスクリプトに収まる
- 評価: 想定質問100問でRecall・回答品質を計測
最大のハマりどころはステップ7の評価だ。「なんとなく動いてる」で本番に出すと、ユーザーが想定外の質問をした瞬間に崩れる。評価データセットの整備は地味だが必須。
2026年のRAGトレンド:観測性とAgentic化
2026年に入って明確に変わったのは、RAG観測性(Observability)プラットフォームが独立カテゴリとして成立したこと。Maxim AIをはじめ、検索精度・回答品質・ハルシネーション率を継続監視するツールが揃ってきた。
エンタープライズRAGの「作って終わり」から「育てる」フェーズへの移行が進んでいる。これは topic-400329-guide-2026-2 でも触れた、AI運用の継続的改善という大きな潮流の一部だ。
もう一つの方向はAgentic RAGへの注目拡大。エージェントが自分で計画を立て、足りない情報を追加検索し、矛盾を検証するループが、法務・金融・調査領域で一部実用事例が報告され始めている(2026-05時点、出典は各ベンダー事例・論文)。応答速度は犠牲になるが、複雑な問いに対する回答品質はStandard RAGと別次元。
よくある落とし穴と回避策
実装現場でよく見る失敗パターンを5つ。
- 「とりあえず全社文書を入れる」: ノイズで精度が下がる。狭く深く始める
- チャンク設計を雑にやる: 検索品質の9割を決める工程を後回しにしない
- 評価データを作らない: 「動いてる気がする」を数値化できない地獄に陥る
- モデル選定にこだわりすぎる: 埋め込みとLLMの組み合わせより、検索設計の方が10倍効く
- 権限管理を忘れる: 機密文書を入れた瞬間、誰がどの情報にアクセスできるかの設計が必須
特に5番目は要注意。RAGは便利すぎるがゆえに、人事評価データや顧客個人情報まで気軽に放り込まれがちで、設計段階でアクセス制御を組んでおかないと事故になる。
編集部の評価
社内マニュアル検索のPoCが最初期に転ぶ原因は、だいたい2つに絞られる。チャンクが大きすぎることと、評価データを用意していないことだ。結局、検索設計を地道にやらないとRAGは動かないという当たり前の結論に戻ってきた。
逆に一度設計が決まると、効果は圧倒的だった。「規程の何条に該当するか教えて」レベルの質問に引用付きで答えてくれる体験は、ChatGPT単体では得られない。社内情報を扱う生成AIにおいてRAGは中心的な選択肢の一つ、という肌感覚は2026-05時点で広がっている(長コンテキストモデルの直接投入など代替アプローチも併存)。
ただしAgentic RAGに関しては、まだ「動くデモ」と「本番投入できる品質」の間に大きな谷がある。応答時間と運用観測性の難しさは想像以上で、当面はStandard RAGをきっちり作り込む方が投資対効果は高い、というのが正直な評価だ。
よくある質問(FAQ)
Q. RAGとファインチューニングはどう使い分ける?
データが頻繁に更新される、引用元を明示したい、コストを抑えたい場合はRAG。逆に文体・専門用語・特定タスクへの最適化が目的ならファインチューニング。両者は排他ではなく併用が標準的で、2026年時点では「ベースはRAG、必要に応じてファインチューニングを足す」が定石。
Q. 日本語のRAGで気をつけることは?
埋め込みモデルの日本語性能でかなり差が出る。OpenAI text-embedding-3-large、Cohere multilingual、BGE-M3あたりが2026年時点で安定して使われている。チャンク分割も英語の単語ベースとは違い、句読点や改行・見出し単位の方が機能しやすい。
Q. ベクトルDBは絶対に必要?
小規模(数百ドキュメント以下)ならインメモリ検索でも動く。ただし更新頻度・検索速度・メタデータフィルタリングを考えるとほぼ必須。最低でもpgvectorで始めるのが安全。
Q. RAGのコストはどれくらい下げられる?
プロンプトキャッシュの活用で、繰り返し同じドキュメントを参照する用途なら半額以下に下がるケースも珍しくない。加えてチャンクの粒度最適化、リランカーによる検索結果の絞り込み、軽量埋め込みモデルへの切り替えで運用コストはさらに圧縮できる。
Q. PoCにはどれくらいの期間がかかる?
データ整備が済んでいれば2〜4週間で「動くもの」は作れる。ただし業務に投入できる品質まで上げるには、評価データ整備と継続改善で追加2〜3ヶ月見ておくのが現実的。「2週間でPoC、3ヶ月で本番候補」が標準的なスケジュール感。



