
Pythonコード数行でAIモデルをAPI化、GPUインフラの調達と管理から解放するサーバーレスプラットフォーム
Beamは、Pythonで書かれたAI/MLモデルやエージェントを、GPUインフラの構築なしに即座にAPIエンドポイントとして公開できるサーバーレスGPUプラットフォームです。Docker、Kubernetes、GPUドライバー設定といった煩雑な作業をすべて抽象化し、デコレータ1つで関数をクラウドにデプロイ可能。推論API、バッチ処理、エージェントのサンドボックス実行など、本番運用に必要な要素を一通りカバーしており、AI機能をプロダクトに組み込みたいスタートアップやMLエンジニア向けに設計されています。
主要機能
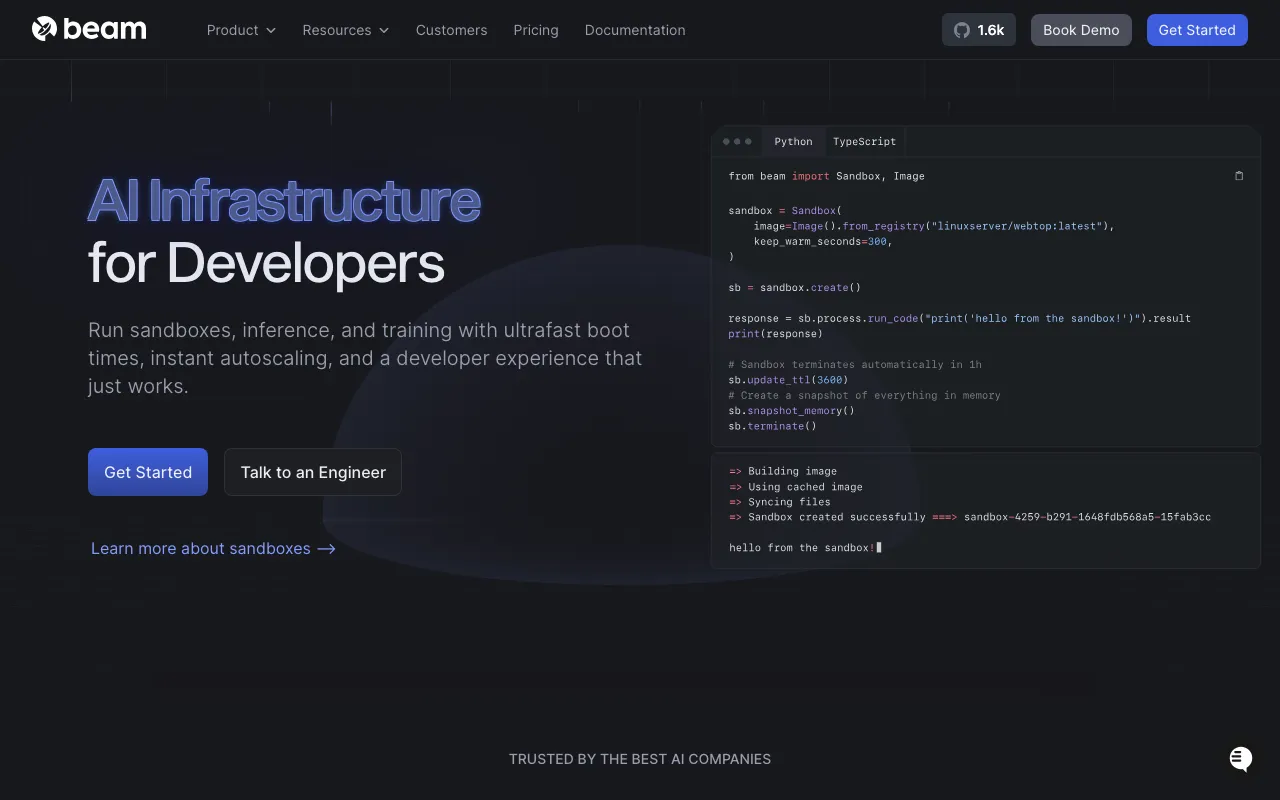
- サブ秒コールドスタート: 一般的なサーバーレスGPUは30〜60秒のコールドスタートが課題でしたが、Beamはチェックポイントリストアとサンドボックススナップショット技術で1秒未満を実現。リクエスト直後のレスポンスが必要な対話型AIに有利です。
- ミリ秒単位の従量課金: 実行時間のみが課金対象で、アイドル時のコストはゼロ。月数百リクエスト規模の検証フェーズなら、専用GPUインスタンス(月10万円〜)と比べ90%以上のコスト削減も可能。
- Python-firstの開発体験:
@endpointデコレータを関数に付けるだけでAPI化。従来のDockerfile作成・k8sマニフェスト記述で数日かかっていた本番デプロイ作業が、数分単位に短縮されます。 - A100/H100まで対応: 軽量モデル向けT4から大規模LLM推論向けH100まで選択可能で、用途に応じた最適化が可能です。
編集部の検証メモ
公開料金プランとサーバーレスGPU市場(Modal、RunPod、Banana等)を比較検討した結果、Beamの優位性は「コールドスタート速度」と「開発体験のシンプルさ」に集約されます。Modalは2025年9月に評価額11億ドルのシリーズBを調達し業界をリードしますが、Beamはより小規模チーム向けに学習曲線を最小化した設計が特徴。1日100リクエスト×平均5秒実行の小規模AIアプリを想定すると、専用GPUインスタンス比で月7〜9万円のコスト削減、インフラ構築工数は初期2〜3週間→数時間に短縮できる試算です。一方で、長時間連続稼働するワークロードでは専用GPUのほうが安価になる損益分岐点があり、利用パターン次第で選択が分かれます。
想定ユーザー
AI機能をプロダクトに組み込みたいスタートアップ、個人開発者、MLエンジニアに向いています。特にプロトタイプから本番運用への移行をスピード優先で進めたいチームに最適です。逆に、24時間定常的に高負荷推論を回すケースや、日本語UI・国内データセンター要件が必須の大企業には不向きです。

