高速API推論で「待ち時間」を消すLLM基盤
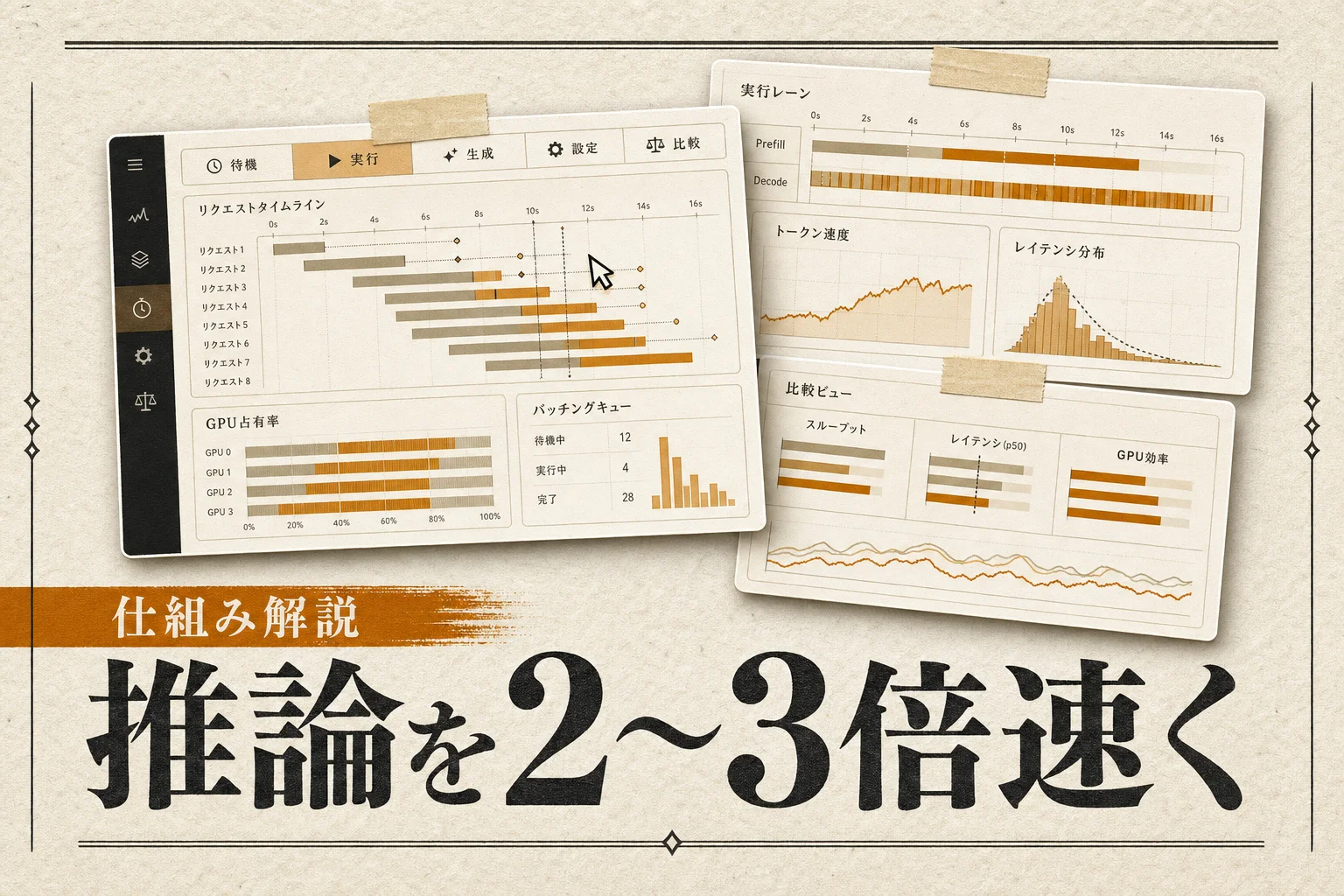
Groqは独自開発のLPU(Language Processing Unit)を搭載した推論専用クラウドで、LlamaやMixtral、DeepSeekなど主要OSSモデルを汎用GPUの数倍〜10倍超のスループットで提供する。OpenAI互換のAPIを叩くだけで既存アプリの推論バックエンドを差し替えられるため、チャットボット、音声エージェント、RAG、社内ナレッジ検索などレイテンシがUXを左右するB2Bプロダクトに向く。
主要機能
- LPUによる超高速推論: Llama 3.3 70Bで毎秒数百トークン級の出力速度。従来GPUで体感30秒かかる長文応答が数秒に収まり、コールセンター用ボットの待機時間を大幅圧縮できる。
- OpenAI互換エンドポイント:
base_url差し替えだけで既存SDK(openai-python等)を流用可能。1〜2行の改修で本番切替でき、PoCの工数を半日〜1日に収められる。 - マルチモデル対応: Llama 4系・Mixtral・Whisper(音声書き起こし)・Qwen系などをワンAPIで横断利用。用途別にモデルを切替えても課金体系が共通で、コスト試算がシンプル。
- 無料枠+従量課金: 開発者向け無料プランで日次トークン上限まで検証可能。本番はpay-as-you-goで、1Mトークン単価がGPT-5.5系の数分の1水準。
編集部の検証メモ
公開料金とベンチマーク資料を突き合わせると、Llama 3.3 70BをGroqで稼働させた場合の出力単価は1Mトークンあたり$0.79前後で、同等規模のGPT-5.5系と比べ概ね1/5〜1/10。月間1,000万トークンを消費するチャットアプリで月$80〜$120のAPI費用に収まる試算となり、レイテンシ短縮による離脱率改善まで含めれば投資回収は1〜2か月が目安。差別化軸は「速度×コスト」の両立で、Together AIやFireworks AIと比較しても出力速度はトップクラス、ただしモデルラインナップはOSS中心でGPT-5.5クラスのクローズドモデルは扱えない点が選定上の分岐となる。
想定ユーザー
既存LLMアプリのレスポンス遅延をAPI差し替えだけで解消したい開発チーム、音声エージェントやリアルタイム要約など低レイテンシが必須のSaaS事業者に最適。一方、GPT-5.5やClaude Opus 4.7などクローズド最上位モデル前提のワークロード、エンタープライズ向けに完全国内データレジデンシーを要求する用途には不向き。