
Modalは、GPU推論、バッチ処理、学習、コード実行環境をサーバレスで構築・実行できるAIインフラプラットフォームです。
ガイドNEW
編集部がツールを4つの軸で評価し、重み付けして100点満点で集計しています。
残7pt分の「信頼性」軸 (運営年数・SLA・セキュリティ認証) は2026後半に追加予定 (現在は調整中で総合スコアには未反映)。
スコアは編集部の調査ベースであり、ユーザー実体験の代替ではありません。
Modal、あなたは?1タップ・匿名OK
Modalは、GPU推論、バッチ処理、学習、コード実行環境をサーバレスで構築・実行できるAIインフラプラットフォームです。

Yuto Suzuki
AI PICKS編集長 ・2026年7月4日更新
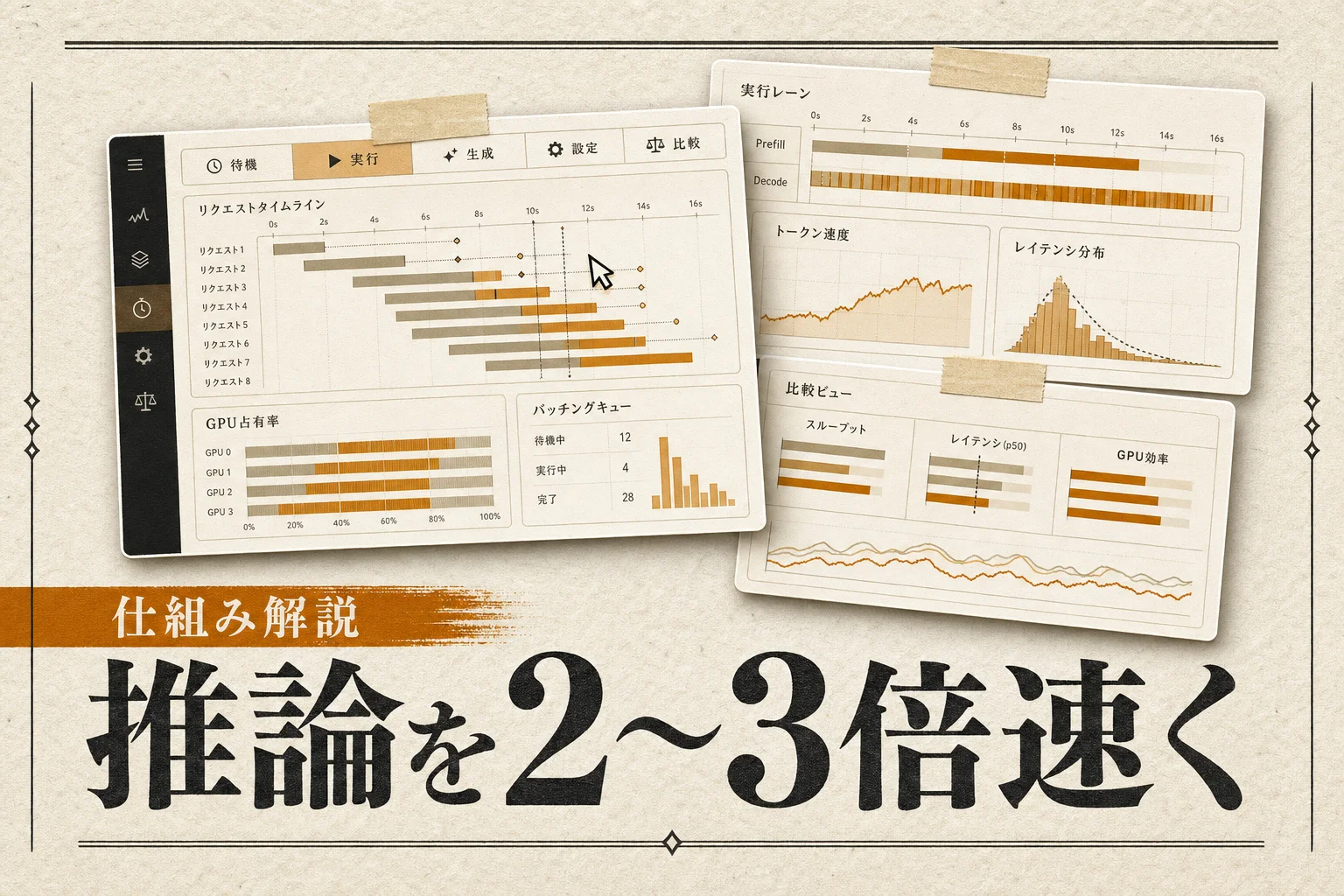
AIクラウド推論+バッチ処理インフラ。必要時のみGPU確保 → 処理後解放のサーバーレス課金、Pythonに数行追加でAIモデルをクラウド実行可能。月使用量ベース価格、個人無料枠あり。Beam/Replicateの競合カテゴリで「開発者体験」に振り切った設計、AIスタートアップの「インフラ管理ゼロ」で運用始める時の本命選択肢。
⚠️ 料金は変動する可能性があります。上記は編集部の調査時点の目安です。 最新の料金は公式の料金ページをご確認ください。
AI PICKS編集部は、注目ツールの料金変動を月次でモニタリングしています。Modalは現在モニタリング対象選定中です。 最新の料金は公式ページをご確認ください。
Modalの 「パイオニア」称号 (Epic) + 200 XPは 最初のレビュアーだけが獲得できる希少バッジ。 あなたの実体験が、後から来る人の意思決定を変えます。
↓ 下のフォームから100文字程度の感想でOK (匿名投稿可)
投稿いただいたレビューは、編集部が事実誤認・誹謗中傷・個人情報をチェック後に公開します。匿名投稿可、投稿後の編集不可です。
あなたのレビューが他のユーザーのツール選びに役立ちます
ModalはAI PICKS編集部が独自スコアで評価し、2.52 / 5.00のスコアを付けています。 下のバッジを公式サイトに掲載すると、第三者評価として信頼性を訴求できます(無料)。
<a href="https://aipicks.jp/tool/modal?utm_source=badge&utm_medium=referral" target="_blank" rel="noopener">
<img src="https://aipicks.jp/api/badge?slug=modal" alt="AI PICKSスコア — Modal" width="220" height="252" loading="lazy" />
</a>このコードを自社サイトに貼ると、AI PICKSの編集部スコアバッジが表示されます。スコアは自動で最新値に更新されます。掲載は無料です。